

PythonでWebスクレイピングを行う際に単一ページでのスクレイピングはできてもページ遷移等が必要となるとできないという方も多いかと思います。
今回はWebサイト食べログを例としてrequestsモジュールとbeautifulsoupモジュールを使用したWebスクレイピングの基本形を解説します。主に流れや形についての解説となりますのでrequestsモジュールとbeautifulsoupモジュールの詳細な使用方法は省きますのでご了承ください。
Webスクレイピングの基本フロー
手動で情報抽出する場合をまず考える。
例えばですが、食べログに掲載されている渋谷区のお店のリストを作りたい。情報としては店名、電話番号、食べログURLの3点を抽出したいとします。
まずは自身で手動でこのリストを作成するとしたらどのようなフローで行いますか?
おそらくほとんどの方は以下の流れで行うのではないかと思います。
このページを一覧ページとします。
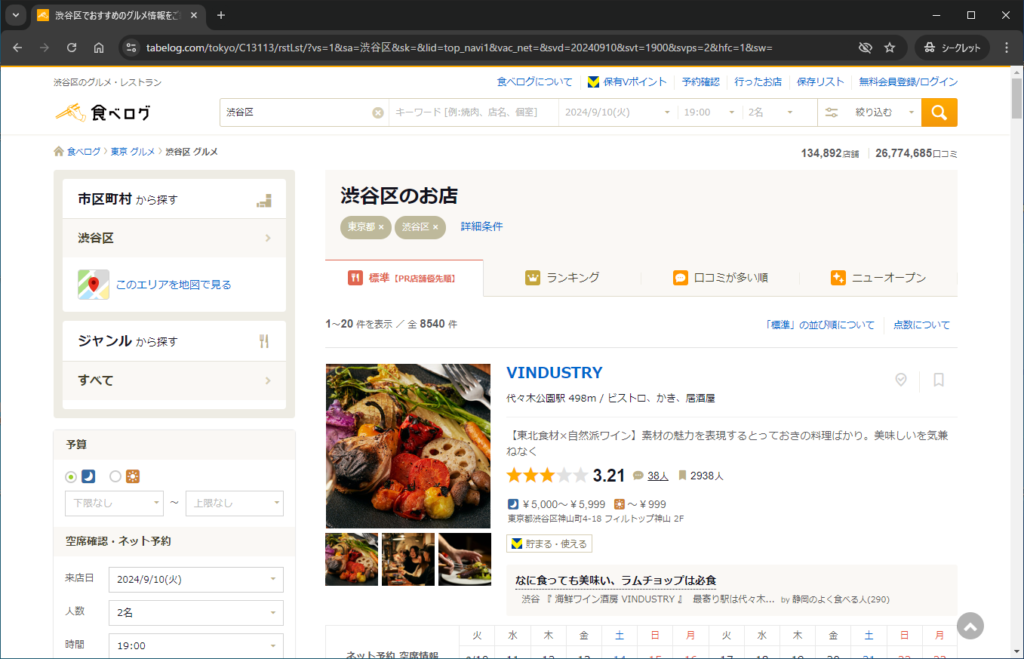
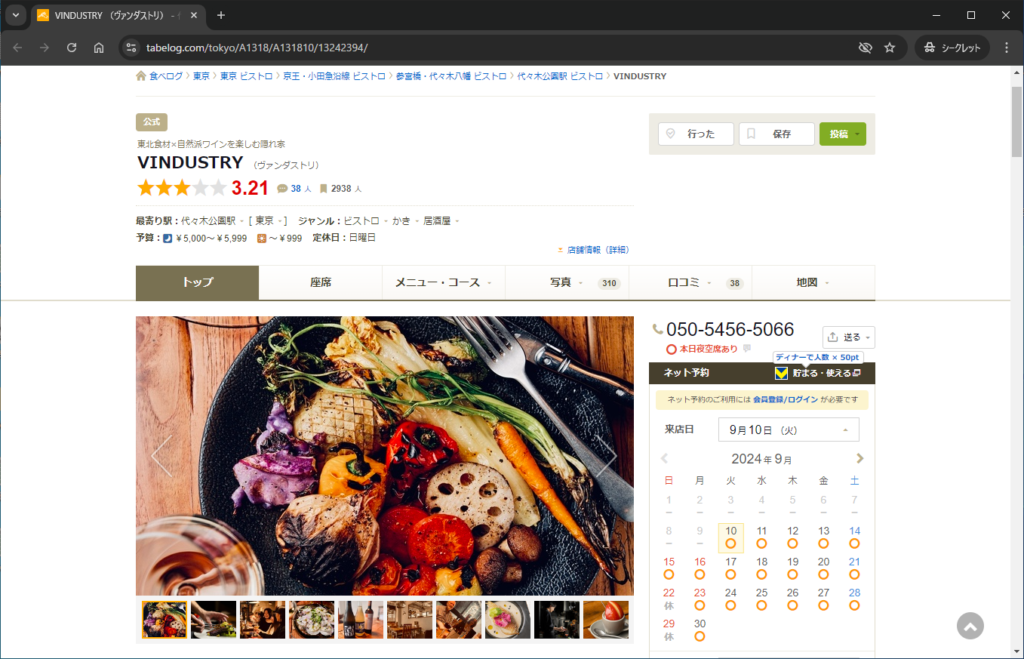
このようにまずは手動で情報抽出する場合を考えることが非常に重要です。
プログラムでのフローに置き換える。
手動で情報抽出する場合を考えることができれば、それをプログラムに置き換えるだけです。
フローチャートで表すと以下のようになります。
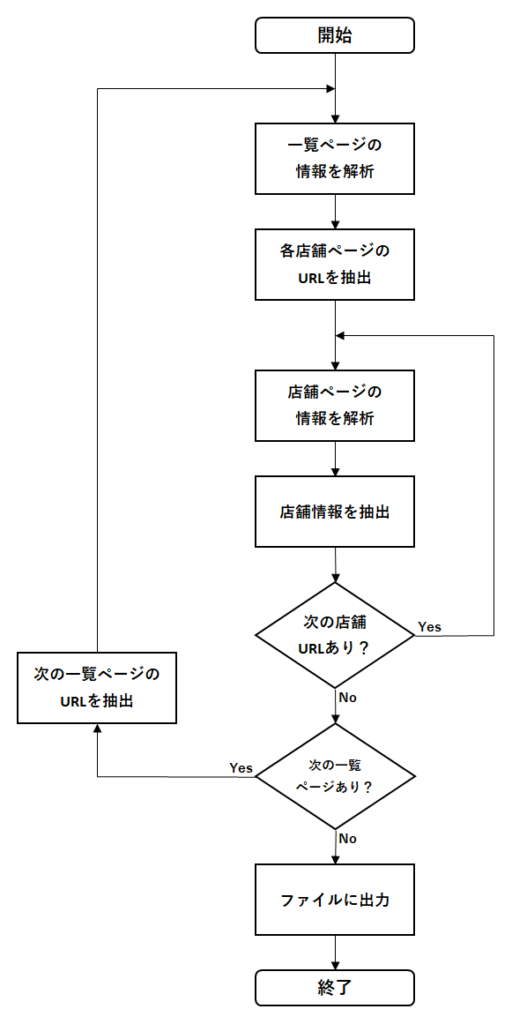
手動で考えた場合との違う点として、一覧ページから各店舗ページのURLを一覧で取得できる(できない場合もありますが)ため、手動の「STEP4 一覧ページに戻る。」というステップは省略されています。つまり、一覧ページに戻らなくても次の店舗URLが分かっているため、一覧ページに戻る必要はなくなるということです。
Webスクレイピングをやっていると分かるのですが、このフローとなることがほとんどです。このフローを基本形として覚えておけば、住宅サイト、通販サイトであっても書くコードは違えど、だいたい応用できます。
あとはフローチャートの各フェーズのコーディングできるかということになってきます。
各フェーズのコーディング
フェーズ1:一覧ページの情報を解析
まずは変数urlに渋谷区で検索した結果のURLを代入し、BeautifulSoupで解析します。
この辺りはrequests + beautifulsoupでWebスクレイピングを行うためのおまじないみたいなものなので解説は省略します。BeautifulSoupの解析器はlxmlを使用していますが、html.parserでもなんでも大丈夫です。私は解析速度が速いということからlxmlを使用しています。lxmlはインストールが必要となりますのでインストールしてご使用ください。
from bs4 import BeautifulSoup
import requests
url = 'https://tabelog.com/tokyo/C13113/rstLst/?vs=1&sa=%E6%B8%8B%E8%B0%B7%E5%8C%BA&sk=&lid=top_navi1&vac_net=&svd=20240910&svt=1900&svps=2&hfc=1&sw='
r = requests.get(url)
r.raise_for_status()
soup = BeautifulSoup(r.text, 'lxml')フェーズ2:各店舗ページのURLを抽出
手動で各店舗ページに移動する際、どこをクリックしますか?リンクがありそうな以下の赤囲み部分をクリックするのではないでしょうか。
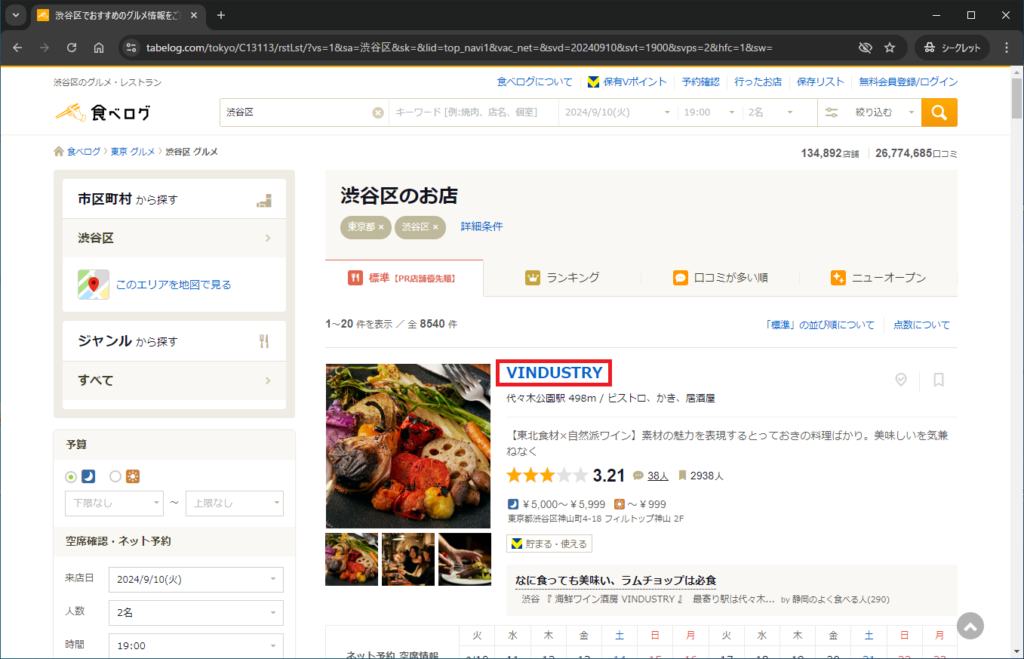
ということはその部分にリンクがついていそうですね。Google Chromeのデベロッパーツールで確認するとaタグがありました。

classに店舗URLのaタグについてそうなlist-rst__rst-name-targetという名前もついていますね。一覧ページの店舗表示件数は20件なのでclass名がlist-rst__rst-name-targetの要素数を抽出し、それが20件であれば店舗URLを示すaタグであるということになりそうなので確認してみます。
from bs4 import BeautifulSoup
import requests
url = 'https://tabelog.com/tokyo/C13113/rstLst/?vs=1&sa=%E6%B8%8B%E8%B0%B7%E5%8C%BA&sk=&lid=top_navi1&vac_net=&svd=20240910&svt=1900&svps=2&hfc=1&sw='
r = requests.get(url)
r.raise_for_status()
soup = BeautifulSoup(r.text, 'lxml')
print(len(soup.select('.list-rst__rst-name-target'))) # 追加
# 実行結果 -> 20結果は20となり、店舗URLを示すaタグを取得できていることが分かりました。ちなみに私はBeautifulSoupのメソッドはfind系ではなく、select系を使用しています。理由としてはselect系で使用するCSSセレクタはスクレイピング用モジュールSeleniumなどでも使用できるからです。
店舗URLを示すaタグを取得できたので各aタグのhref属性を取得できれば各店舗ページのURLリストshop_urlsを作成できます。内包表記を使用した以下のコードを使用します。
from bs4 import BeautifulSoup
import requests
url = 'https://tabelog.com/tokyo/C13113/rstLst/?vs=1&sa=%E6%B8%8B%E8%B0%B7%E5%8C%BA&sk=&lid=top_navi1&vac_net=&svd=20240910&svt=1900&svps=2&hfc=1&sw='
r = requests.get(url)
r.raise_for_status()
soup = BeautifulSoup(r.text, 'lxml')
shop_urls = [a_tag.get('href') for a_tag in soup.select('.list-rst__rst-name-target')] # 追加フェーズ3:店舗ページの情報を解析
取得したshop_urlsをfor文でループすることで店舗URLごとに処理を行うことができます。つまり、「次の店舗URLあり?」の部分はPythonのイテレータという概念により判定を入れなくてもfor文が勝手に行ってくれます。
そのfor文のループ内でBeautifulSoupを使って解析します。
また、サーバに負荷をかけすぎないよう、リクエスト後に1秒の待機処理を入れてサーバへのリクエスト間隔が最低でも1秒以上となるようにtimeモジュールのsleep関数も追加しています。
from time import sleep # 追加
from bs4 import BeautifulSoup
import requests
url = 'https://tabelog.com/tokyo/C13113/rstLst/?vs=1&sa=%E6%B8%8B%E8%B0%B7%E5%8C%BA&sk=&lid=top_navi1&vac_net=&svd=20240910&svt=1900&svps=2&hfc=1&sw='
r = requests.get(url)
r.raise_for_status()
sleep(1) # 追加
soup = BeautifulSoup(r.text, 'lxml')
shop_urls = [a_tag.get('href') for a_tag in soup.select('.list-rst__rst-name-target')]
##### ここから追加 #####
for shop_url in shop_urls:
shop_r = requests.get(shop_url)
shop_r.raise_for_status()
sleep(1)
shop_soup = BeautifulSoup(shop_r.text, 'lxml')フェーズ4:店舗情報を抽出
一番の目的である店舗情報を抽出します。ただし、抽出する情報によってコードは異なってきますので詳細は割愛します。もし、抽出したい情報をどのように指定すればよいか分からないといった場合やコメント等でご連絡いただけましたらできるだけ対応いたします。
基本的には冒頭にd_listという名前でスクレイピング用の空のリストを宣言し、私の場合は辞書型でデータを追加していきます。辞書型でデータを追加することで最後のフェーズでファイルに出力する際に簡単にDataFrameへ変換でき、DataFrameのメソッドを使用することでCSVファイルやExcelファイルへの出力が容易に可能となります。
また、d_listのappendメソッドで辞書型のデータを挿入後、どのようなデータなのかを確認するため、print関数でd_listの最後のデータを出力しています。
from time import sleep
from bs4 import BeautifulSoup
import requests
url = 'https://tabelog.com/tokyo/C13113/rstLst/?vs=1&sa=%E6%B8%8B%E8%B0%B7%E5%8C%BA&sk=&lid=top_navi1&vac_net=&svd=20240910&svt=1900&svps=2&hfc=1&sw='
d_list = [] # 追加
r = requests.get(url)
r.raise_for_status()
sleep(1)
soup = BeautifulSoup(r.text, 'lxml')
shop_urls = [a_tag.get('href') for a_tag in soup.select('.list-rst__rst-name-target')]
for shop_url in shop_urls:
shop_r = requests.get(shop_url)
shop_r.raise_for_status()
sleep(1)
shop_soup = BeautifulSoup(shop_r.text, 'lxml')
##### ここから追加 #####
d_list.append({
'店名': shop_soup.select_one('.display-name').text.strip(),
'電話番号': shop_soup.select_one('.c-table th:-soup-contains("お問い合わせ") + td').text.strip(),
'食べログURL': shop_url,
})
print(d_list[-1])フェーズ5:次の一覧ページがあるか判定
次の一覧ページがあるか判定する場合、手動ではどのように判定するか考えます。私であればページ下部の次の20件という文字があるかで判定します。
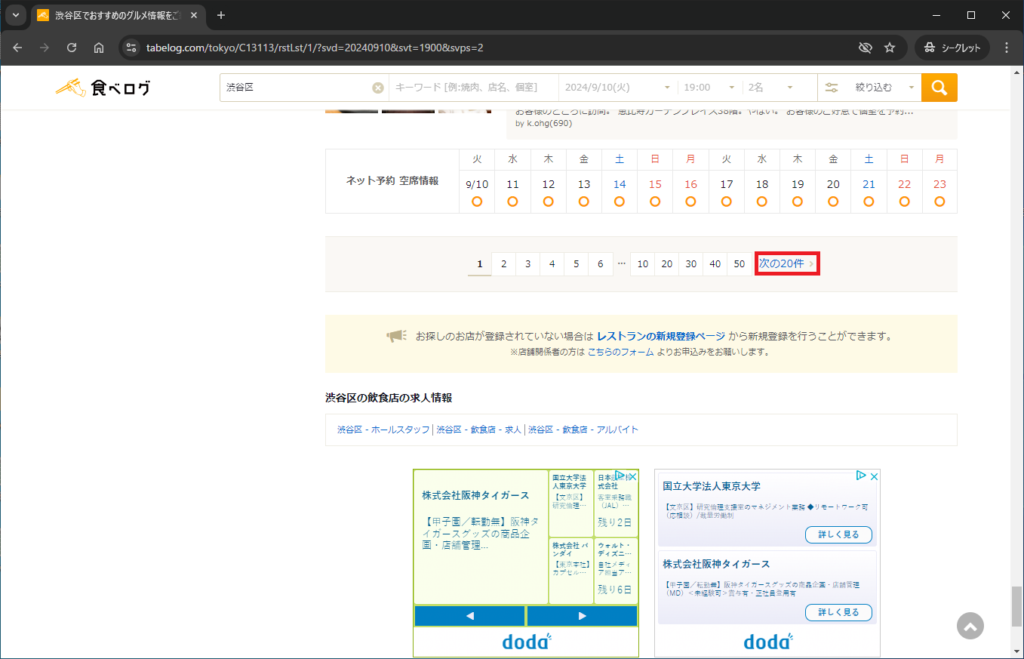
次の20件という文字があるかで判定するということは最終ページには当然、次の20件という文字があってはいけません。それも確認します。
最終ページに次の20件という文字がないことを確認できれば、次にGoogle Chromeのデベロッパーツールでどのようなタグなのかを確認します。
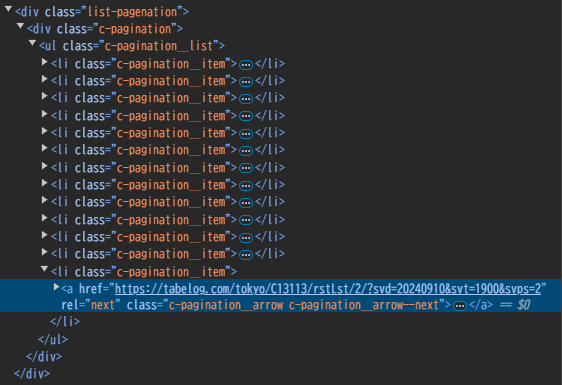
aタグでrelに次ページを表しそうなnextという名前がついていますね。他にもそのような要素があったら嫌なのでページネーションを表しそうな名前がついている親要素のタグにも制限をかけてnext_a_tagを取得します。
このnext_a_tagが一覧ページにある限り、ループを継続するのでwhile文を使用してnext_a_tagがない場合にwhileを文を抜ける記述とします。
from time import sleep
from bs4 import BeautifulSoup
import requests
url = 'https://tabelog.com/tokyo/C13113/rstLst/?vs=1&sa=%E6%B8%8B%E8%B0%B7%E5%8C%BA&sk=&lid=top_navi1&vac_net=&svd=20240910&svt=1900&svps=2&hfc=1&sw='
d_list = []
while True: # 追加
r = requests.get(url)
r.raise_for_status()
sleep(1)
soup = BeautifulSoup(r.text, 'lxml')
shop_urls = [a_tag.get('href') for a_tag in soup.select('.list-rst__rst-name-target')]
for shop_url in shop_urls:
shop_r = requests.get(shop_url)
shop_r.raise_for_status()
sleep(1)
shop_soup = BeautifulSoup(shop_r.text, 'lxml')
d_list.append({
'店名': shop_soup.select_one('.display-name').text.strip(),
'電話番号': shop_soup.select_one('.c-table th:-soup-contains("お問い合わせ") + td').text.strip(),
'食べログURL': shop_url,
})
print(d_list[-1])
##### ここから追加 #####
next_a_tag = soup.select_one('.c-pagination__list a[rel="next"]')
if next_a_tag is None:
breakフェーズ6:次の一覧ページのURLを抽出
フェーズ5で次の一覧ページがあった場合の記述を追加します。先ほど取得したnext_a_tagのhref属性を取得することで次の一覧ページのURLを取得できます。変数urlを取得したURLに置き換えることで次のループでは次の一覧ページにおいてフェーズ3~5を繰り返すことになります。
また、現在何ページ目が完了したのかを表示したいため、変数pageを追加しています。
from time import sleep
from bs4 import BeautifulSoup
import requests
url = 'https://tabelog.com/tokyo/C13113/rstLst/?vs=1&sa=%E6%B8%8B%E8%B0%B7%E5%8C%BA&sk=&lid=top_navi1&vac_net=&svd=20240910&svt=1900&svps=2&hfc=1&sw='
d_list = []
while True: # 追加
r = requests.get(url)
r.raise_for_status()
sleep(1)
soup = BeautifulSoup(r.text, 'lxml')
shop_urls = [a_tag.get('href') for a_tag in soup.select('.list-rst__rst-name-target')]
for shop_url in shop_urls:
shop_r = requests.get(shop_url)
shop_r.raise_for_status()
sleep(1)
shop_soup = BeautifulSoup(shop_r.text, 'lxml')
d_list.append({
'店名': shop_soup.select_one('.display-name').text.strip(),
'電話番号': shop_soup.select_one('.c-table th:-soup-contains("お問い合わせ") + td').text.strip(),
'食べログURL': shop_url,
})
print(d_list[-1])
next_a_tag = soup.select_one('.c-pagination__list a[rel="next"]')
if next_a_tag is None:
break
##### ここから追加 #####
url = next_a_tag.get('href')フェーズ7:ファイルに出力
ここまで来ればあとはスクレイピングした情報が格納されている変数d_listをCSVファイルやExcelファイルに出力するだけです。pandasモジュールのDataFrameのto_csvメソッドやto_excelメソッドを使えばわずか2行で出力できます。
変数d_listをDataFrameに変換し、CSVファイルに出力する場合はto_csvメソッド、Excelファイルに出力する場合はto_excelメソッドを使用します。
import pandas as pd
df = pd.DataFrame(d_list)
df.to_csv('output.csv', index=False, encoding='utf-8') # CSVファイルに出力する場合
df.to_excel('output.xlsx', index=False) # Excelファイルに出力する場合最終コード
ここまでで解説した最終的なコードを掲載します。
from time import sleep
from bs4 import BeautifulSoup
import pandas as pd
import requests
def main():
url = 'https://tabelog.com/tokyo/C13113/rstLst/?vs=1&sa=%E6%B8%8B%E8%B0%B7%E5%8C%BA&sk=&lid=top_navi1&vac_net=&svd=20240910&svt=1900&svps=2&hfc=1&sw='
d_list = []
page = 1
while True:
r = requests.get(url)
r.raise_for_status()
sleep(1)
soup = BeautifulSoup(r.text, 'lxml')
shop_urls = [a_tag.get('href') for a_tag in soup.select('.list-rst__rst-name-target')]
for shop_url in shop_urls:
shop_r = requests.get(shop_url)
shop_r.raise_for_status()
sleep(1)
shop_soup = BeautifulSoup(shop_r.text, 'lxml')
d_list.append({
'店名': shop_soup.select_one('.display-name').text.strip(),
'電話番号': shop_soup.select_one('.c-table th:-soup-contains("お問い合わせ") + td').text.strip(),
'食べログURL': shop_url,
})
print(d_list[-1])
print(f'{page}ページ完了')
next_a_tag = soup.select_one('.c-pagination__list a[rel="next"]')
if next_a_tag is None:
break
url = next_a_tag.get('href')
page += 1
df = pd.DataFrame(d_list)
df.to_csv('output.csv', index=False, encoding='utf-8')
if __name__ == '__main__':
main()プログラムで行うにしてもまずは手動で行う場合を考えることが非常に重要かと思います。
これを読んでページ遷移等が必要な場合のWebスクレイピングの苦手意識を払拭いただければ嬉しいです。

コメント